O cenário é o seguinte: Você está virado para uma parede do vizinho, com uma pistola na mão, puto da vida, e atira… Com a cabeça mais fria e sabendo que é ruim de mira pra caramba, quer medir onde acertou, na parede (esperemos que não no vizinho!), mas, como não pode invadir a propriedade dele, precisa calcular o ponto do estrago à partir do ponto onde você se encontra. Como fazer?
Este é o típico problema de intersecção entre um plano e uma linha. Essa “linha”, no caso, tem uma origem (a pistola) e um destino (algum lugar da parede). Para simplificar, nossa parede é triangular, que torna simples obter a equação do plano em que ele se encontra.
Como vimos antes, um plano é definido como tendo um vetor diretor unitário (um vetor “normal”) e uma distância da projeção de qualquer ponto neste plano em cima deste “normal”. No entanto, estamos interessados apenas na coordenada de um ponto em cima do plano, ou seja , onde é um ponto no plano.
Nós já conhecemos, pelo menos, 3 pontos no plano que compõem o triângulo e, para computação gráfica, nosso triângulo é definido de forma ordenada, quer dizer, a ordem dos vértices é conhecida (sentido anti-horário)… Assim, um vetor sobre o plano, definido como , onde é um dos vértices e o ponto é o que queremos obter, é sempre perpendicular ao vetor normal . Ou seja, .
Ao mesmo tempo, a linha da trajetória da bala pode ser calculada como tendo origem num ponto e direção , onde esse último vetor é unitário e será escalonado por um fator , formando uma simples equação linear:
Note que, das duas equações, , , e são conhecidos. Não sabemos o valor de e queremos conhecer o vetor . Substituindo a equação acima na equação que descreve todos os pontos no plano, temos:
Com isso, encontramos o valor de que nos possibilita calcular o ponto exato sobre o plano onde a bala estragou a parede do vizinho sacana… Só tem dois problemas…
Se você for realmente ruim de mira, o produto escalar pode ser zero e a divisão acima torna-se impossível. Felizmente existe uma interpretação geométrica para esse caso: Você atirou paralelamente à parede. A direção da bala () e o vetor normal da parede são perpendiculares! E essa é a condição de teste para sequer pensarmos em continuar com o cálculo…
O outro problema é o sinal de . Se obtivermos um valor negativo, significa que atiramos para o outro lado, em direção oposta à parede… Claro que, neste caso, obteremos um ponto de intersecção como se a bala tivesse atingido um ponto atrás do atirador. É interessante notar que, se estamos voltados para a parece, e apontarão em sentidos opostos, mas o vetor também aponta para o sentido oposto do vetor normal, o que nos dará um positivo, mas se estivermos apontando para o outro lado, os vetores unitários estarão voltados para o mesmo sentido, mas os outros dois ainda continuarão opostos, dando um negativo!
Isso quer dizer que, além de verificarmos se não é zero, podemos verificar se ele é negativo… Só assim a bala atingirá o plano da parede (não necessariamente a parede em si, mas o plano!). Dito isso, a equação final para localizar o ponto fica assim:
Sempre fiquei meio cabreiro sobre a existência do qualificador centroid em GLSL. O que diabos é uma “centroide”? Uma consulta rápida mostra que centroide é o centro geométrico de um conjunto de pontos… Mas, o qualificador centroid aplica-se a um simples vetor. A pergunta que vem à mente é óbvia: WTF?! Mas, volto a ela no final…
Recentemente topei com um interessante problema que parecia ser simples, até você pensar um cadinho nele. Em essência, o problema era este (na verdade ele é declarado de maneira diferente, veja o problema C deste link — lista de problemas indicada por Fausto Luis Dias Soussa. Valeu, Fausto!):
Dados 4 pontos no espaço: a, b, c e d, não co-planares e diferentes, forma-se um tetraedro (uma “pirâmide” com 4 faces triangulares). Dado também um ponto x, que não se encontra no interior desse tetraedro, determine quais das 4 faces do tetraedro estão visíveis por um observador localizado no ponto x.
PS: Os supostos resultados corretos, no texto original estão errados!
Vimos, em um post passado, que para determinar a visibilidade de um triângulo basta calcular a equação do plano () e calcular a distância do observador ao plano… Na equação, o vetor é calculado através de dois dos lados do triângulo, e a distância d é calculada a partir da projeção do vetor formado por um dos vértices (não nulo) e o origem do sistema de coordenadas com o vetor normal (revise tudo aqui e aqui).
O “problema” do problema…
Acontece que para obter o vetor normal apontando para o lado “potencialmente visível” da face precisamos informar os pontos que formam essa face em um sentido bem definido. Quando modelamos um objeto para ser usado em computação gráfica informamos as coordenadas da face no sentido anti-horário, por exemplo… Isso tem que ser assim porque, dessa maneira, podemos garantir que o produto vetorial dos vetores calculados com base nas coordenadas do triângulo criarão um vetor normal que aponta “para fora” do objeto… No problema acima os pontos são dados sem essa contextualização, então temos que fazer alguma coisa para saber o que é o “lado de dentro” do tetraedro e o que é o lado “de fora”. Para isso, seria conveniente se tivéssemos um ponto garantidamente localizado “dentro”…
Centroide ao resgate!
Para polígonos convexos o cálculo do “centro” (centroide) é bem simples… Basta usar uma média aritmética simples: . Onde n é a quantidade de vértices… No nosso caso, 4 (uma vez que teremos 4 planos, um para cada triângulo). Neste ponto não precisamos calcular a centroide de cada um dos triângulos nos planos, já que a centroide do tetraedro ainda é a média aritmética simples de cada um dos vértices!
A figura abaixo mostra o que é um centroide em um triângulo (que é um polígono convexo!). O que vale para um triângulo, vale também para um tetraedro…
Centroide de um triângulo
A principal característica de uma centroide é que este ponto estará sempre dentro do triângulo…
Temos agora nosso ponto da “meiuca” do tetraedro. Podemos calcular as equações dos planos de cada triângulo e comparar os vetores normais com o vetor formado entre um dos vértices do triângulo (em uma face) e a centroide. Depois de obtidos os vetores normais, basta projetar o vetor formado entre a centroide e um vértice e verificar se o resultado é negativo. Um resultado negativo, nessa projeção, significa o vetor normal aponta no sentido oposto do vetor que aponta para a centroide, ou seja, que ele aponta “para fora” do objeto… É o que queremos!
Agora que temos os 4 vetores normais, um para cada face, basta calcular a distância do plano à origem do sistema de coordenadas, conforme eu já mostrei em artigo anterior… Assim, temos as equações dos 4 planos completas… É só uma questão de calcular a distância do observador x a esses planos… se a distância for positiva (se x estiver na frente do plano), então o triângulo que está sobre esse plano é visível, senão, não é…
Update: Desculpe, inadvertidamente apaguei o código fonte no Google Drive. Mas a descrição acima, acredito, é bem direta e de simples implementação, uma vez que você entenda o produto escalar e as projeções do vetor centroide→plano (do triângulo).
O qualificador “centroid” do GLSL
Eis o “problema” com alguns shaders: O fragment shader, por exemplo, interpola coordenadas de pontos intermediários entre vértices. Se quisermos calcular as coordenadas de um ponto num estágio anterior e repassá-lo sem interpolação para o próximo estágio, a palavra reservada centroid informa isso ao OpenGL. A ideia é que, se eu calculei uma centroide, baseadas nos vértices do objeto, não quero que esse valor seja modificado mais adiante por causa de interpolações… É isso! 🙂
Em notação matemática, especialmente na Física, uma equação do tipo usa o sinal de igualdade para expressar que duas ou mais grandezas, geralmente diferentes, são equivalentes. Existe uma grandeza do lado esquerdo (energia, neste exemplo) e outras do lado direito (massa e velocidade). É assumido, mas não necessariamente obrigatório, que a expressão do lado esquerdo seja uma consequência da expressão do lado direito…
Do ponto de vista matemático, poderíamos obter o valor da velocidade da luz, c, se tivéssemos os valores de E e m, desse jeito: … Acontece que isso é, do ponto de vista Físico, inválido… O sinal de igualdade não é uma simples atribuição e as grandezas geralmente não são “intercambiáveis”.
Voltando a computação gráfica:
Da mesma maneira, quando escrevemos algo como , embora o resultado, no lado esquerdo, seja um vetor e a variável independente, do lado direito, seja também um vetor (), estamos lidando com dois “espaços” distintos. Para entender isso, considere que a equação acima pode ser compreendida como: , onde I e M são matrizes de transformação geométricas. Ao multiplicar um vetor por uma matriz estamos “transformando” o vetor, usando vetores diretores de outro espaço, diferentes do “espaço canônico”.
Chamo aqui de “espaço canônico” o espaço definido pelos vetores diretores , e .
A primeira equação (nesta parte) nos diz algo assim: “O vetor , que está no espaço canônico, é equivalente ao vetor , transformado pela matriz M (que, possivelmente, especifica um espaço diferente do canônico)”… Como queremos obter , temos que usar a matriz inversa de I e obter a equação . E, já que a matriz de identidade é ortogonal, então , podemos, seguramente ignorar , neste caso.
Mudando os vetores diretores:
Em resumo, ao usar a identidade do lado esquerdo, dizemos que o resultado terá a base canônica. Mas, se alterarmos essa transformação estaremos, de fato, alterando os vetores diretores do lado esquerdo. Estaremos mudando o sistema de coordenadas!
Eis um exemplo simples: Considere que temos um vetor na base canônica e tenhamos uma base arbitrária A contendo 3 vetores diretores ortogonais como abaixo:
Repare que essa matriz de transformação possui o vetor diretor e rotacionados em 45° no sentido anti-horário (), mas o vetor diretor manteve-se. Ou seja, nesse exemplo, nosso novo sistema de coordenadas será rotacionado em 45° para a esquerda em torno do eixo z (veja a próxima figura!).
Como sabemos que a matriz acima é ortogonal (toda matriz de rotação é!), então . Assim, transpondo a matriz e multiplicando-a pelo vetor obteremos:
Graficamente você pode comprovar que o ponto está exatamente no mesmo lugar do ponto , mas num sistema de coordenadas diferente!
Mudança de base.
Veremos que isso é útil para orientar a câmera, mas ainda não resolvemos o problema do posicionamento… Quero dizer: Acabamos de rotacionar um sistema de cordenadas, mas não o transladamos ou escalonamos ainda…
O sistema de coordenadas da câmera:
A analogia da câmera usa 3 vetores: Um vetor de posicionamento (), um vetor “para frente” () e um vetor “para cima” (). O vetor obviamente nos diz em que ponto do espaço do “mundo” a câmera (ou o “olho”) está. Os outros dois nos dizem o que ela vê (“para frente”) e a rotação da câmera, indireta, em torno do próprio eixo, com o vetor “para cima”.
A câmera “canônica” está posicionada em e possui os vetores e .
O que estraga essa especificação é que o é de uma “grandeza” diferente dos outros dois. Os vetores e são diretores, enquanto que o outro não é. Para resolver isso e para termos uma analogia melhor para a câmera, podemos usar três vetores diferentes: , (indica uma posição no espaço do mundo para onde a câmera aponta) e . O vetor pode ser calculado como . Assim, temos dois vetores diretores ( e e, para completar o trio de vetores diretores, temos que calcular um vetor lateral: (repare na ordem!).
Com isso, temos os 3 vetores diretores da espaço da câmera (view space)… Mas, nem todos precisam ser, necessariamente, unitários! De fato, apenas o vetor não precisa ser unitário, os outros dois têm que sê-lo… O vetor frontal nos dará uma mudança de escala do novo sistema de coordenadas, emulando um distanciamento da câmera da origem do “sistema de coordenadas original” e, a combinação desses três nos dará uma rotação do sistema de coordenadas.
Calculando o novo sistema de acordo com a câmera:
As três equações abaixo nos dão os vetores diretores do espaço da câmera…
Suponha que a câmera seja canônica… Isso nos dará: , e .
A matriz do novo sistema de coordenadas será . O motivo de invertermos o sentido do vetor diretor ? É que o vetor diretor do eixo z, no sistema de coordenadas original, aponta para o lado oposto do vetor , do espaço da câmera! Outro detalhe importante é o recalculo do vetor . Isso é necessário porque ele poderá não ser perpendicular aos outros dois, originalmente… Imagine o cenário onde você altere e … Neste caso o vetor poderá ficar “desalinhado”. O último produto vetorial garante que, além de “alinhado”, ele será unitário.
No exemplo acima a matriz de transformação da câmera fica:
Outra interpretação do porquê podemos modificar a escala de , mantendo os outros dois unitários, é que, para posicionar a câmera em qualquer lugar do espaço basta fastá-la da origem e depois rotacioná-la… Ao mudar a escala do eixo z do espaço da câmera, fazemos exatamente isso!
Essa complicação toda vale à pena?
Bem… separando as transformações do lado esquerdo da equação temos que os objetos podem ser transformados do espaço do modelo para o espaço da câmera (view) em apenas uma tacada… Usando apenas uma matriz!
No OpenGL essa matriz tem o nome de modelview. Ela, em essência é calculada como , onde a primeira a matriz do “modelo” transforma os vértices dos objetos no espaço do modelo para o “mundo” e a matriz da câmera (ou “visão”) transforma os vértices que estão no “mundo” para o espaço da câmera, alterando a base do sistema de coordenadas, como mostrado acima.
Fornecendo apenas uma matriz de transformação para os shaders poupamos muito tempo de processamento e, por isso, vale à pena!
O espaço da câmera não é o mesmo espaço de “projeção”:
Lembra-se do frustum? Eu havia dito que ele serve para projetar os vértices do espaço do “mundo” para o espaço de recorte (o plano near!)… Bem… não é bem isso… ele projeta os vértices do espaço da câmera para o plano near!
Além da matriz modelview, temos a matriz de projeção (aquela do frustum) que tem o nome de perspective projection matrix ou, simplesmente, projection. Isso é importante entender:
Na sequência de transformações, a matriz model modificará as coordenadas dos vértices do espaço do modelo para o espaço do mundo… Segue a matriz inversa da câmera, que transformará o sistema de coordenadas do mundo para o sistema da câmera (view)… Essas duas são a modelview… Logo depois a matriz de projeção é multiplicada e transforma os vértices no espaço da câmera para o espaço de recorte (clip).
Como OpenGL mistura as matrizes do modelo e da câmera em uma só, é conveniente que, para obter os planos do frustum (porque ele também será reorientado, jundo com a “câmera”) multipliquemos as duas matrizes, e , mas com a matriz do modelo ajustada para a matriz identidade.
Repare que, para cada objeto na cena, a matriz de modelo conterá transformações para posicionar e orientar o objeto no espaço do mundo. Assim, temos que ter, em algum momento, uma matriz de modelo “canônica” para lidar com a cena como um todo… A versão antiga do OpenGL (versão 2.1) tinha um artifício para garantirmos isso: Uma pilha de matrizes… Ajustávamos uma matriz modelview para toda a cena e a empilhávamos… depois ajustávamos a mesma matriz para cada um dos conjuntos de vértices de objetos em cena, empilhando e “desempilhando” novas matrizes. Depois disso, nos restava a matriz empilhada em primeiro lugar, onde poderíamos obter os planos do frustum… Isso não existe mais…. Você deve saber com quais matrizes está lidando em cada execução de códigos de vertex shaders…
Mostrarei, em outro artigo, como extrair as equações dos planos do frustum a partir dessas duas matrizes, bem como a maneira de comparar a geometria de objetos contra elas…
O que temos até agora? Vetores que compõem uma lista de vértices que, por sua vez compõem listas de triângulos que podem ser texturizados. Além disso, temos uma câmera no meio do “universo”, que podemos posicionar mudando a orientação do universo (não o da câmera!)… Muito legal, mas isso nos deixa com um problema: Numa cena qualquer, quais listas de triângulos devemos desenhar primeiro?
Você pinta como o pintor pinta?
Numa animação bidimensional é “fácil” decidir o que vai ser desenhado primeiro: O fundo da cena, é claro! A técnica é a mesma usada por um pintor de um quadro: Pinte a paisagem primeiro e depois os objetos mais próximos, por cima! Isso cria a ilusão de tridimensionalidade. Parece que o que está “por cima” está mais perto do que o fundo…
É claro que, do ponto de vista computacional, isso envolve o uso de algum algoritmo de ordenação. Precisamos determinar aqueles objetos que têm componente z maior (ou, “menor” porque estamos usando a regra da mão direita e a câmera aponta para , lembra?) e desenhá-los antes de todos os outros. O processo tem que ser repetido para os objetos que sobram até que não reste objetos a serem desenhados…
Ahhhh… se fosse tão simples!
Plantando árvores…
Embora tenhamos que manter listas de triângulos para cada objeto, não podemos manter uma “lista” de objetos, pura e simples… Um dos motivos é que, num algoritmo de ordenação tradicional como bubble sort ou quick sort, precisamos de uma “chave” para fazer a comparação entre dois itens. Essas “chaves” tendem a ser fixas, imutáveis durante a vida do elemento de um array… No caso de objetos no espaço tridimensional, suas posições e orientações podem mudar com o tempo, alterando a “chave”, dinamicamente… O que torna o uso desses algoritmos tradicionais meio difícil.
Se houvesse uma maneira de criarmos uma estrutura de dados onde esses elementos já estariam ordenados assim que inseridos nesse “container”, seria ótimo! Felizmente tal estrutura existe: Árvores.
Dividindo e conquistando…
Ao invés de lidarmos com testes feitos contra todos os objetos individuais numa cena, podemos dividir o “mundo” em “submundos”, colocando apenas um ou, pelo menos, alguns poucos, objetos em cada parte (ou “partição”) do mundo. Para demonstrar isso, imagine que estamos olhando um “mundo” de cima. Nesse mundo temos dois objetos (duas bolinhas coloridas):
Na figura da direita, cada quadrado interno é um submundo do grande mundo mostrado na figura a esquerda. Aqui, conseguimos colocar cada um dos objetos em seu próprio submundo. O motivo de fazermos isso ficará claro daqui a pouco… Quero apenas que você repare que um particionamento desse tipo pode ser feito com uma estrutura de árvore. O nó raiz corresponde a todo o mundo visível (a figura da esquerda). Esse nó possui 4 nós filhos, cada um deles correspondendo a um pedaço do todo, uma fração do mundo (uma parte). Essa árvore com 4 nós filhos para cada nó pai é chamada de quadtree.
O nó filho que possuir um ou mais objetos associados a ela terá um nó “folha” contendo uma lista de objetos… Bem… talvez não… podemos aproveitar a estrutura de árvore e particionar um submundo em quatro outros sub-submundos:
Desse jeito podemos criar uma árvore contendo todos os objetos na cena, cada um deles em seu próprio “pedacinho de chão”, bastando aumentar o número de níveis da árvore… Existirão casos onde o “loteamento” individual não será possível e precisaremos deixar dois ou mais objetos juntos, mas isso não é lá tão problemático assim (quem sabe não rola uma amizade?).
Outra coisa que não fica evidente nas figuras é que essas partições não precisam ser feitas exatamente na metade de cada eixo.
Qual é a vantagem em dividir o mundo em “partes”?
Esse particionamento, à primeira vista, não parece ser lá muito vantajoso. Estamos apenas criando esses “loteamentos”, mas precisaremos fazer testes de visibilidade (por exemplo) com todos os objetos, certo?
Essa é a beleza do particionamento em sub-espaços… Considere que temos uma câmera na partição onde está a bolinha azul:
A câmera possui um frustum (indicado bem de leve na figura) e ele “vê” apenas os sub-espaços da bolinha azul e o vazio, ao lado. Sabendo disso, pra que iríamos nos preocupar em fazer testes com os outros sub-espaços que não estão visíveis?!
Dividindo o mundo em sub-espaços podemos selecionar apenas aqueles que estejam visíveis e somente depois decidir quais objetos devem ser testados contra o frunstum!
E quanto a 3D?
Estender o raciocínio de uma quadtree para 3D é simples: Ao invés de usarmos linhas para dividir o mundo, usamos planos. Isso nos dá um particionamento de um cubo em 8 “sub-cubos” e, por isso, usa-se uma octree. Uma árvore com 8 nós filhos… Mas, o princípio é o mesmo que o da quadtree, explicada acima.
Octrees.
Eis um exemplo de uma figura, ao estilo Minecraft, usando uma octree:
A áreas cinzentas são partições que contém algo.
Com relação à visibilidade, basta imaginar uma câmera, apontando para a cabeça do Buda: O frustum “verá” apenas algumas partições, todas as outras podem ser seguramente ignoradas, durante o desenho do objeto!
O “crime” não é perfeito com essas “caixas”!
Olhando para a figura acima podemos ver alguns problemas: Existem partições que têm apenas um pedacinho do objeto e outras que possuem “pedações”. Isso acontece com objetos que não são “quadradões”…
Algumas aplicações gráficas usam octrees pela simplicidade e porque não precisam ser tão detalhistas… É o caso do Minecraft, onde todos os objetos são cúbicos ou formados por cubos (chamados de voxels)… Algumas outras aproveitam a simplicidade e o fato de que, mesmo com algumas perdas, não existem efeitos colaterais. É o caso de animações em “espaços abertos”.
Os outros casos precisam de um particionamento espacial mais “refinado”, mais preciso, mesmo que seja um pouco mais complicado… Mas, o princípio é o mesmo: dividir o espaço em sub-espaços cada vez menores, com o objetivo de selecionar apenas aqueles que são visíveis… Por tabela, usando as árvores, podemos determinar qual desses sub-espaços está na frente ou atrás de outros…
Uma sigla que impressiona:
O mais famoso dos métodos de particionamento espacial é chamado de BSP (Binary Spatial Partitioning — Particionamento espacial binário). Diga para alguém que você está modelando uma “árvore binária de particionamento espacial” e vão te olhar como se você fosse um deus!
Exemplo de BSP com 2 planos.
Uma BSP faz exatamente a mesma coisa que uma octree faz: Divide o mundo em partições usando planos divisores. Mas, diferente das octrees, a BSP usa planos arbitrários que não estão, necessariamente, alinhados com a mesma orientação do sistema de coordenadas. Isso permite, dentre outras coisas, que esses sub-espaços tenham “cantos” que não sejam cúbicos, diminuindo o desperdício de espaço…
Eis um exemplo, ao lado, de uma árvore BSP montada à partir da figura acima. Os nós do lado esquerdo estão “na frente” dos planos (os vetores normais dos planos divisores nos dão a orientação). Os do lado direito, “atrás”. Este exemplo simples não parece lá muito convincente, mas, uma vez que determinarmos que o que está “na frente” do plano B não está dentro do frustum, não precisamos nos preocupar com a sub-árvore à esquerda do nó deste plano.
Existem outras vantagens: Uma árvore BSP é uma árvore binária comum (daí o nome “binário”), cada nó pai possui apenas dois nós filhos. E é perfeitamente aceitável que usemos uma árvore balanceada para criação dos nós… Uma árvore binária balanceada tem a vantagem de poder ser percorrida, do nó raiz até um dos nós “folha” em um tempo constante (proporcional a (logaritmo, na base 2, de n).
Lembre-se que estamos lidando com triângulos como primitivos para formação de qualquer objeto na cena e que eles são contidos em um e apenas um plano. Podemos usar um desses triângulos de um objeto para obter um plano divisor! E, com isso, podemos obter tantos planos divisores que quisermos até obtermos apenas um objeto por sub-espaço.
Na prática, queremos a menos quantidade de planos divisores possíveis, para termos uma árvore pequena e de rápido manuseio… E esse é um dos pontos fracos das BSPs: Inserir um novo plano divisor não é tão simples como é com uma octree!
Particionamento, usando BSPs:
Um dos problemas que tornam as BSPs complicadas é que se tivermos dois planos não paralelos, um deles “cortará” o outro em dois. Lembre-se que um plano não tem “limites”, é uma superfície que se estende infinitamente. Assim, quando um plano “corta” o outro teremos que usar o mesmo plano duas vezes, em nós diferentes e, assim, alguns poucos objetos contidos nos dois diferentes sub-espaços podem também ser “divididos”, deixando um pedaço de um lado e outro pedaço de outro.
Ahhh… e quais objetos estarão contidos em um sub-espaço? Ou melhor, qual é a geometria ideal para um sub-espaço? Bem… é consenso que criar sub-espaços convexos é a melhor coisa possível. Lembra-se que conceituamos um polígono convexo como aquele onde podemos traçar uma linha qualquer entre seus lados e ela tocará apenas dois desses lados? O mesmo aplica-se aqui, mas, de novo, ao invés de linhas usa-se planos e ao invés de “lados”, usa-se “faces” ou “triângulos”…
Com sub-espaços não convexos podemos ter deformações tais que alguns polígonos que normalmente estariam invisíveis estarão visíveis e vice-versa… Com sub-espaços convexos isso não acontece… Mas, diferente do que fizemos para uma superfície simples, não podemos simplesmente “triangulizar” um sub-espaço (ou, transformá-lo num tetraedro). O motivo é simples: Acabaríamos com muitos sub-espaços para lidar, a BSP ficaria enorme e o processamento lento. A limitação de criar sub-espaços convexos é suficiente para gerar BSPs grandes o suficiente para lidarmos com a cena, mas não tão grandes que gastaríamos muito tempo…
Pela estrada afora…
Não é surpresa descobrir que, mesmo usando árvores binárias, a maneira de “caminhar” pelos nós não é o tradicional… Não basta usar apenas algoritmos pre-order, in-order ou post-order, como numa árvore binária comum. A tarefa não é lá tão simples… Uma vez descoberto o nó onde a câmera está e escolher os objetos dentro do frustum contidos nesse nó (usando uma busca in-order, por exemplo), depois de lidar com os objetos nesse sub-espaço, teremos que refazer nossos passos para determinar se a câmera pode ver outros sub-espaços, determinando se estes estão contidos no sub-espaço do frustum (que é composto por 6 planos!) e, se puder, escolher os objetos que estão dentro do frustum e assim por diante… É evidente que, assim como a busca in-order, esse processo também é recursivo…
Mas, existem outros problemas: Alguns sub-espaços podem estar “ocultos” por alguma barreira existente entre eles (o exemplo também mostra isso!)… Para resolver isso teremos que usar outros algoritmos, chamados de testes de oclusão. Falarei sobre eles em outra oportunidade…
Ao invés de dividir os sub-espaços com planos arbitrários que não tocam objeto algum (como ficou aparente nos exemplos acima), podemos escolher planos contidos em objetos como divisores… Por exemplo, podemos escolher planos de “paredes”… Dessa forma, o plano divisor também contém um obstáculo, que pode esconder, parcialmente, outro sub-espaço. Os buracos vazios neste plano podem ser modelados no que se chama portais. Ao verificar se outro sub-espaço está visível, pode-se verificar se, entre eles, existe um portal… Se existir, pelo menos parte do outro sub-espaço estará visível, senão, podemos ignorá-lo.
Que floresta!
Já que BSPs são complexas, do ponto de vista de construção, e as octrees não são. Misturar as duas pode ser uma boa ideia: Podemos usar BSPs para os objetos estáticos da cena e assim podemos ter uma BSP pré-calculada e podemos usar octrees para os objetos dinâmicos, contidos entre as “paredes”.
Falei antes aqui que a rotação pode ser feita de forma vetorial, ao invés da maneira matricial, através de um troço chamado quaternion. Para entendermos o que diabos é isso temos que revisar o conceito de números complexos e a sua associação com vetores.
Um número complexo tem a notação ou , onde as constantes a é chaamada a parte “real” e b, a parte “imaginária”. Óbviamente não se trata de imaginação, no sentido de que tudo é possível, mas somente a nomenclatura oposta de “real” (o que não é real é “imaginado”, não é?). A parte “real” também é óbvia. Refere-se ao domínio ℝ. Uma maneira de pensar em números complexos é encará-los como uma forma algébrica de especificar um vetor :
Vetor .
Da mesma maneira podemos usar uma representação complexa para a representação de vetores no ℝ3. Aliás, devemos usar ℝ4, aproveitando o valor real isolado como fator de escala, assim como num sistema de coordenadas homogêneas..
Quaternions são compostos de um valor “real” e três partes imaginárias: , onde i, j e k são os componentes imaginários. Para facilitar a associação de um quaternion com vetores no espaço tridimensional vou inverter a notação para , onde d é o valor real isolado. Essa notação pode ser escrita, também como , onde . O motivo de usarmos delimitadores < e > nessa notação é que podemos querer escrever algo assim: .
Os valores complexos e os vetores diretores…
Ao invés de usar uma notação vetorial para escrever um vetor qualquer (assim ó: ), podemos escrever . Mas também podemos escrever a mesma coisa usando a notação complexa, usando os valores i, j e k, complexos, que seguem características mostradas na tabela ao lado.
Para garantir que esses valores sejam ortogonais entre si, ao multiplicar um item de uma linha com o de uma coluna da tabela temos: ij=k, jk=i e ik=j. O motivo dessa última multiplicação não ser ki=j é que estamos obedecendo à regra da mão direita…
Ainda, temos . Repare, também, que o produto entre esses valores não é comutativo, ou seja, , por exemplo. Esse último fato te lembra de alguma coisa? Essas multiplicações (entre i, j e k) lembram o produto vetorial entre os vetores diretores de um sistema de coordenadas ortogonal (por exemplo, ), não lembram?
Quaternions “puros”:
O conceito de “pureza” de quaternions é importante, como veremos mais adiante… Um quaternion “puro” é aquele onde o valor escalar (o valor “não vetorial”) é zero. Ou seja, um quaternion do tipo é “puro”.
Operações com quaternions:
Operações elementares de adição e escalonamento são evidentes. Por exemplo, , para e , definido de maneira similar, então . No escalonamento: . Mas a coisa começa a ficar interessante com a multiplicação…
E é dai que os conceitos de produto vetorial e produto escalar vêm… É interessante notar que, se usarmos quaternions puros, obteremos .
O recíproco de um quaternion:
A divisão por um quaternion, assim como acontece com matrizes, não é tão fácil… Para obtermos um quaternion recíproco (ou seja: ) temos que usar o “macete”:
Onde é o conjugado do quaternion q, onde invertemos apenas o sinal do vetor , refletindo-o (se então ). O tamanho de um quaternion é obtido da maneira tradicional: .
É fácil observar que, se o vetor contido no quaternion puro for unitário (), então .
Rotações, usando quaternions:
Lembra da “equação mais bonita de todas“? Ela pode ser extendida para quaternions puros e unitários (onde ), facilmente:
Com esse quaternions e seu recíproco podemos rotacionar qualquer vetor em torno de um vetor , deste jeito: , onde o quaternion p é dado por e o quaternion q contém o vetor unitário e o ângulo θ, de rotação em torno deste vetor, como mostrado acima.
O detalhe esqusiito está no uso da metade do ângulo de rotação (). A interpretação geométrica dessa multiplicação de quaternions pode ser entendida como se o primeiro rotacionasse o vetor até a metade do caminho e o conjugado terminasse o serviço. De fato, se resolvermos a equação , de maneira “complexa” (multiplicando todos os fatores contendo os complexos i, j e k), obteríamos uma matriz de rotação desejada… Esse exercício não é assim tão simples, já que o que estamos, de fato, fazendo é transformar o sistema de coordenadas e rotacionando o quaternion p ao mesmo tempo!
A vantagem de usar quaternions nas rotações:
Algumas vantagens óbvias são:
Quaternions ocupam menos espaço que matrizes. Uma matriz 3×3 ocupa 9 floats, o vetor unitário onde “giraremos em torno” ocupa mais 3 floats e ainda temos o ângulo de giro. Gastando um total de 13 floats. No caso do uso de 2 quaternions: 2 vetores (6 floats) e um ângulo, totalizando 7 floats;
Rotações com quaternions efetuam menos operações (cerca de 60% das operações necessárias no uso das matrizes).
Vale lembrar que, se estamos lidando com quaternions puros e com um vetor unitário , então teremos . O que facilita um bocado as contas…
A vantagem menos óbvia é que rotações via quaternions evitam um problema chamado gimbal lock. O termo “gimbal lock” descreve um fenômeno onde, ao rotacionar eixos individuais, às vezes, um conjunto de rotações é indistinguível de outra, como fica claro na animação abaixo:
Repare que “yaw” e “roll” fazem a mesma coisa.
Com a rotação facilitada, em torno de um vetor unitário arbitrário, garantimos que esse tipo de coisa só acontencerá se for intencional!
Por mais refinados que sejam os cálculos envolvendo objetos tridimensionais, conseguiremos atingir apenas um certo de nível de realismo. A limitação não está nem tanto na matemática, mas no poder de processamento de seu computador… E aidna temos o componente artístico da coisa toda.
Eu, por exemplo, sou uma droga no que se refere a “arte”. Hoje em dia, não consigo desenhar uma linha reta sem o auxílio de uma régua. Com o mouse então, é impossível… Esteja ciente de que se você pretende criar alguma animação ou jogo com um visual “maneiro”, terá que ser um artista fluente.
Existem, basicamente, dois tipos de artistas envolvidos em computação gráfica: Os escultores e os pintores. Os escultores esculpem (o que mais, né?) os modelos tridimensionais. Esse trabalho pode ser feito tando de forma digital, diretamente, quanto com esculturas no mundo real e depois, de alguma forma, escaneadas e inseridas num modelo matemático (no computador). Sobre o processo de modelamento, falarei em outra oportunidade. O que nos interessa, hoje, é a turma que pinta esses modelos.
Decalques
O artista que pinta os modelos o faz através de decalques. Ai do lado tem um exemplo simples do que é um decalque, mas estou certo de que você já tinha mexido com isso antes. Isso é bem semelhante ao que acontece dentro da aplicação: Uma imagem é estampada, pixel por pixel, sobre alguma superfície tridimensional. Ela sofre alguma deformação por causa da interpolação necessária para fazê-la caber na superfície e este é o aspecto matemático da coisa..
Do ponto de vista da computação gráfica, um decalque é uma figura plana e retangular onde certas regiões dentro deste retângulo são mapeadasna superfície do objeto que o receberá. Da mesma forma que a figura abaixo é uma planificação da geóide que é a forma original da superfície da terra:
Superfície da terra planificada, ou seja, um MAPA.
Essa figura, retangular, não condiz exatamente com o formato da geóide, que é mais ou menos assim:
E você achando que a terra era “esférica” ou uma “elipsóide”!
É claro que Isso ai também é um mapa, contendo um código de cores para as distâncias da superfície em relação ao centro do planeta. Mas, serve para dar uma idéia do formato real do objeto onde o mapa, acima, será aplicado para criar o aspecto conhecido do planeta…
Note que a textura não condiz com a figura real (especialmente nos polos)l Ela é distorcida… E o mapeamento deve levar isso em consideração. Essa mágica é feita usando um sistema de coordenadas específico para as texturas, diferente do sistema de coordenadas do modelo.
Mapeando uma textura “plana” num objeto
O leitor mais atento deve ter percebido que estou falando aqui de texturas bidimensionais, fazendo a analogia do decalque… Existem também texturas unidimensionais (apenas uma linha) e tridimensionais (diversas camadas de texturas bidimensionais, ou imagens). Falo de texturas bidimensionais porque são as mais usadas em computação gráfica.
Sujeito simpático, huh?!
Eu disse que uma textura bidimensional é um retângulo, como contido em qualquer arquivo gráfico (jpeg, png, pcx, …). Os cantos inferior esquerdo e superior direito são atribuídos as coordenadas (x,y) entre (0,0) e (1,1), respectivamente, no espaço das texturas. A figura ao lado, desse senhor simpático com cara de trollface, demonstra como os cantos de uma textura são mapeados neste sistema:
Embora uma imagem “chapada” como essa (note: falo da imagem, não o sujeito!) possa ser usada como textura, é comum que ela tenha pedaços “transparentes”. Mas, mesmo assim ela será retangular. A transparência resulta do componente alpha de cada quarteto de valores por pixel (lembra-se? R, G, B e A). A figura da geóide, acima, possui um canal alpha (salve-a em disco e edite com o photoshop ou gimp e você verá!).
Porém, existe um problema… A origem do sistema de coordenadas num arquivo gráfico é o canto superior esquero, não o inferior… Por esse motivo, é conveniente carregar o arquivo gráfico de trás para frente, como fiz neste código. Isso transfere a figura, que está no quarto quadrante, no arquivo gráfico, para o primeiro quadrante, que é o que o OpenGL espera.
Atributos de um vértice:
A forma de mapear uma imagem sobre uma superfície é adicionando um atributo à lista de vértices. Até o momento os vértices eram encarados como vetores no espaço tridimensional . Agora, além desses três valores, temos mais dois: , onde s corresponde à componente horizontal e q, à vertical (veja a minha cara de malandro ai em cima!). Assim, além da posição do vértice no espaço do modelo, temos que especificar a coordenada deste vértice no espaço das texturas para que o OpenGL saiba quais pixels deve copiar da textura para a superfície e, ainda mais, como ele vai interpolar os pixels contidos na textura para caber na superfície, depois de transformada no espaço do mundo.
De forma geral, os vértices costumam ser estruturas que contém alguns atributos:
Cada um desses conjuntos de floats é dito ser um “atributo” de um vértice. Todos os fragmentos contidos no intervalo entre dois vértices são interpolados. Não somente a coordenada do fragmento intermediário, mas também o vetor normal, a cor e a coordenada de textura.
Quanto à essa interpolação, OpenGL fornece dois modelos: Near e Linear. No modelo de interpolação near os pixels mais próximos do desejável são simplesmente copiados para a superfície. No modelo linear uma interpolação é realmente feita. Imagine isto: Sua textura tem 128 pixels no sentido horizontal e a superfície a qual ela será estampada tem 256. No modelo de interpolação near, cada pixel da textura será repetido duas vezes. No modelo linear, o OpenGL calculará a cor do pixel intermediário que está faltando na superfície.
Finalmente, um exemplo!
Eis um exemplo com um cubinho animado contendo uma textura com diversos mapeamentos para cada face do mesmo:
Usando apenas uma textura!
Para obter esse efeito com apenas uma textura, atribuímos, para cada face, composta de 4 vértices, o par correspondente ao pedaço da textura que desejamos. Abaixo, temos o pedaço da textura usado pela face frontal, que mostrará o “1”:
Mapeando a porção “1” na primeira face.
A textura está do lado esquerdo. O cubo, texturizado (depois que fiz o mapeamento que falarei abaixo) à direita.
O canto superior esquerdo da textura tem coordenada (0,0). Já o canto inferior direito, (1,1). A porção que será colocada na face frontal contém coordenadas entre esses valores. A lista de vértices da face foi definida assim: O primeiro vertice é o do canto superior direito e os restantes ocorrem no sentido anti-horário — o centro de gravidade do cubo está em . A face frontal encontra-se em :
Nº do vertice
(x,y,z)T
(s,q)T
1
(1,1-1)
(0.3, 0.9)
2
(-1,1,-1)
(0.1, 0.9)
3
(-1,-1,-1)
(0.1, 0.5)
4
(1,-1,-1)
(0.3, 0.5)
Esses valores de s e q são chutes (deu preguiça de pegar os valores reais!)… Mas, dá pra ver que os cantos do retângulo selecionado na textura têm correspondência direta, na mesma ordem, com a sequência de vértices da face do cubo. Repare também que, na animação, face do “6” está invertida… Isso ocorreu porque, para obter o efeito visual que seria “correto”, eu teria que inverter os cantos de seleção do retângulo na textura (rotacionando-o 180°), o que eu não fiz.
O que estamos fazendo aqui é somente recortar uma porção da textura e colando essa porção numa face do cubo.
Restrições do OpenGL:
O exemplo acima foi construído no Blender. No OpenGL existe uma restrição relativa ao tamanho da textura. Ela deve ter comprimento e largura múltiplos de 2n. Isso quer dizer que texturas com tamanho 120×120 não podem ser usadas. Elas teriam que ter tamanho 128×128. O limite superior para o tamanho das texturas geralmente é de 4096×4096.
PS: No OpenGL 2.1 em diante (com certeza no 3 em diante) essa restrição, relativa ao tamanho múltiplo de 2n, não existe mais… Mas a restrição do tamanho total continua lá, é claro!
Texturas tão grandes não são recomendáveis… Uma textura assim teria 64 MB de tamanho (4 bytes por pixel). Se você usar texturas com tantos detalhes para tudo quanto é objetos na cena, rapidamente a memória de sua placa de vídeo será exaurida. Especialmente porque ela serve não apenas para incorporar texturas, mas também recebe lista de vértices (com seus atributos), shaders, matrizes, etc…
Ainda… Existe uma técnica quamada mip mapping, que atribui texturas de tamanhos diferentes para a mesma superfície… A idéia é que, quanto mais “longe” o objeto estiver do observador, menor é o nível de detalhe (LOD, Level of Detail) e, portanto, mais imprecisa a textura pode parecer… Você não consegue ver detalhes num quadradinho de 9 pixels de tamanho, então, pra que usar uma textura de 16 Mpixels de resolução?
E quanto às texturas distorcidas?!
O exemplo do cubo faz um mapeamento direto entre a textura e o objeto… De um lado temos um quadrado (a face do cubo) e do outro temos também um quadrado selecionado na textura… Só que alguns softwares permitem “esculpir” os modelos (Blender, por exemplo) e, ainda, pintá-los digitalmente sobre o próprio modelo esculpido. A textura final ficará com um aspecto que não lembra em nada o produto final, eis um exemplo:
Esticando a pele… 😉
No fim das contas, é a figura à direita que é armazenada, juntamente com os vértices do modelo (não mostrados aqui)… O resultado final é o da esquerda.
A figura da direita, óbviamente, não foi feita deste jeito… O artista foi pintando o modelo, à esquerda, é obteve o mapa com aspecto esquisito, como se estivesse esfolado o pobre do rapaz. No mapa, à direita, pode-se ver os polígonos que compõem o modelo, mas apenas como guia. A textura final não os possui… Tudo o que está fora desses polígonos simplesmente é ignorado no produto final…
Texturas não servem apenas para fazer decalque…
Texturas não porecisam ser usadas apenas como uma espéce de maquiagem digital… Elas podem ser usadas para distorcer o próprio modelo, por exemplo:
Textura usada para distorcer o modelo.
O Yoda da esquerda provavelmente é um modelo com bem menos detalhes. A textura, à direita, é usada para distorcer, de leve, a reflexão da luz, dando um efeito chamado de “solavanco” (bump). A superfície final fica menos “homogênea” do que realmente é, no modelo original, graças aos disturbios introduzidos pela textura…
Falarei sobre bump mapping em outro artigo. É suficiente reconhecer que essa técnica é usada para “bagunçar” um pouco os vetores normais dos vértices e dos fragmentos intermediários…
Texturas podem ser usadas para muitas outras coisas que não apenas como “decalque”. Podemos usar texturas para simular iluminação, por exemplo… E, mesmo como decalque, pode ser usada de maneiras surpreeendentes… Para simular reflexão, por exemplo! Olhe isto:
Não, a esfera não está realmente “refletindo” o ambiente!
O que está acontecendo ai em cima é que uma textura correspondente ao “ambiente” está sendo aplicada (com mapeamento inverso e esférico). Basta inverter o sentido dos vetores diretores associados a s e q da matriz de transformação do espaço de textura para “espelhá-la”, mudando o sentido dos eixos (apenas s foi mudado aqui). Quanto ao mapeamento esférico, isso é feito mudando os atributos de cada vértice do objeto.
Mapeamento esférico é um treco complicado, que explicarei em outro texto…
Empilhando texturas:
Outra analogia com decalques é que podemos usar texturas sobrepostas. Isso é particularmente interessante se as texturas tiverem componentes alpha, ou seja, se tiverem níveis de transparência…
O efeito de sombra dinâmica (mudando os pontos de luz a sombra acompanha) pode ser feito com texturas, calculadas em tempo real e aplicadas sobre as texturas dos objetos na cena. E, é claro, não são apenas as sombras… Podemos aplicar reflexão (como mostrada acima) e outros efeitos como radiosidade (a influência das cores de um objeto em outro).
Jogue algum jogo onde o personagem aciona uma lanterna e você está vendo todos esses efeitos citados através de sobreposições de texturas:
Cena de “The Last of Us”.
Claro que o engine do jogo é sofisticado o suficiente para calcular os efeitos de uma textura na outra… Sombras poderão ser causadas causadas pela textura da luz da lanterna, por exemplo! Como sempre, tudo o que você vê na cena é uma enganação: Não existe luz e não existem sombras…
Não… não quero ser tão deprimente te dizendo que “é difícil ter coragem num mundo tão cheio de gente que você pode perder tudo de vista e a escuridão dentro de você pode te fazer se sentir pequeno” (sério! essa é a letra da música!). Quero só falar um cadinho sobre “true colors”, sobre as cores “lindas como o arco-íris” (𝅘𝅥𝅮 beautiful as the rainbow… 𝅘𝅥𝅮)!
Antes eu disse que inclusive as cores podem ser vistas como grandezas vetoriais. Temos 3 componentes: Vermelho (R), Verde (G) e Azul (B), que correspondem exatamente à sensibilidade dos “sensores” que temos em nossos olhos… Isso é um fato, mas eu também disse que existe mais um componente: Alpha. Esse valor não é uma cor, mas um índice de transparência, usado para “misturarmos” cores. Assim, uma cor pode ser expressa como o quarteto (r,g,b,a)T.
Todo sistema de coordenadas define um “espaço”. Com as cores não poderia ser diferente, do ponto de vista matemático…
Os espaços das cores:
Lá na época em que ainda existia “educação artística” nas escolas (mais uma vez, eu, aqui, entregando minha idade!) aprendíamos que misturar tinta azul com tinta amarela dava uma tina de cor verde… Infelizmente, do ponto de vista fisiológico, isso é completamente FALSO! Verde é uma das cores primárias e amarelo é uma cor composta (amarelo é a mistura pura de verde e vermelho no espectro eletromagnético da luz!). Isso é fácil comprovar… Pegue um color picker (uma daquelas dialog boxes que selecionam cores) e coloque R e G no máximo, zerando B:
Veja os campos “Current” e “R”, “G” e “B”.
Você obtém um amarelo puro… Mas, porque, então, ao misturar as tintas, temos um efeito diferente?
Acontece que existem diferentes “espaços” de cores. Cada espaço leva em consideração características físicas do meio onde haverá mudança de frequência nos fótons que refletem sobre a superfície (ou fótons que são emitidos por ela). Fisiológicamente somos capazes de perceber apenas o vermelho, o verde e o azul, as três cores primárias. É nosso cérebro que faz a interpolação e obtemos “cores” intermediárias.
O espaço de cores associado com nossa fisiolgia é demonstrado no seguinte diagrama, que mostra o espaço “aditivo” de cores… Esse é o espaço RGB:
Ao somarmos o verde e o vermelho obtemos amarelo. Se somarmos todas as frequências do espectro luminoso conseguimos o branco…
Já em superfícies reflexivas, como numa folha de papel ou numa parede (e também na tinta, que é composta de minúsculas partículas), a interação dos fótons com o meio é subtrativa. Ou seja, na colisão das “partículas de luz” (fótons) eles são absorvidos pela superfície e a energia dessa colisão é transformada em calor. Os fótons refletidos também sofrem atenuação energética, alterando a frequência da onda eletromagnética que percebemos como luz… Com isso, o que observamos é uma “diferença” (como se fosse cr=1-ci, onde cr é a cor refletida e ci é a cor incidida na superfície). A percepção é diferente e, portanto, usa um espaço diferente. O espaço CYMK (Ciano, Amarelo, Magenta e Preto [Key]):
Note como algo que “lembra” o azul (ciano) misturado com amarelo nos dá verde! Mas isso não significa que, se você misturar as três cores primárias do espaço CYMK, vai obter preto… Por isso ele consta do espaço nesse modelo. Mas, também é evidente que se misturar várias tintas, a cor final provavelmente será escura… Entendeu agora porque aquelas impressoras jato-de-tinta têm que ter o cartucho preto, além dos outros três (Ciano, Magenta e Amarelo)?
É claro que esses diagramas nos dão apenas uma pequena quantidade do espectro de cores. Eles existem apenas para efeitos comparativos.
RGB e CYMK são, basicamente, os dois espaços mais práticos no que se refere à mistura de cores. No etnanto, eles não são os únicos. Você deve ter notado, lá em cima, que existem campos com nomes esquisitos como H,S e V, no seletor de cores do GIMP. HSV é o espaço de cor que especifica a matiz ou tonalidade (Hue), a saturação (S) e o valor (V) de uma cor. Esse é um modelo que arranja as cores de um jeito tal que os componentes RGB ficariam mais “fáceis” de selecionar numa aplicação de edição de imagens. Enquanto o espaço RGB lembra um cubo (com suas componentes x,y e z mapeadas para as cores primárias), o espaço HSV lembra um cilindro:
Aquele gradiente de cores lá no color picker do GIMP, por exemplo, é uma planificação de um “pedaço do bolo”, ou de um setor do cilindro no espaço HSV.
Aliás, o espaço HSV é aditivivo também, assim como o RGB. Existe outro espaço relacionado com o CYMK chamado HSL (onde L vem de lighting ou “brilho”).
RGB, CYMK e HSV não são os únicos espaços:
Existem muitos outros. Em arquivos de vídeo e imagens digitais, por exemplo, costuma-se usar o espaço YUV, onde Y é o sinal de lunimância (intensidade luminosa) e os componentes U e V são valores diferenciais de crominância (frequência de uma cor). O espaço de cores YUV é útil na transmissão de sinal de vídeo…
Por que é interessante saber sobre esses espaços?
Bem…. se você souber que superfícies que emitem fótons (lâmpadas, o sol, uma vela) são percebidas de forma aditiva e superfícies que refletem luz (pelo menos as que absorvem mais do que refletem) são percebidas de forma subtrativa, na hora que tiver que criar um efeito de reflexão realista usando fragment shaders deverá prestar atenção a esse detalhe…
Normalizando o espaço de cores RGB:
Por que, no color picker, usamos valores entre 0 e 255 para os componentes de cor? É que a intensidade de cada componente é mapeada em 8 bits. Normalmente temos 8 bits para R, 8 para G e o mesmo tanto para B, criando um grande valor de 24 bits. Em HTML podemos especificar uma cor via seus componentes RGB, em hexadecimal. O amarelo, lá em cima é especificado como 0xffff00. O azul puro é 0x0000ff (ou 0xff) e o vermelho puro seria 0xff0000.
Ora, 224=16777216, ou seja, 24 bits nos dão uma matiz de 16.8 milhões de cores possíveis. Não é por acidente que 8 bits tenham sido escolhidos como o valor máximo de cada componente. Acontece que, para o espaço de cores RGB, o olho humano só consegue perceber mais ou menos, essa quantidade de cores. No entanto, somos mais sensíveis com relação ao espaço CYMK. Quer dizer, somos mais sensíveis à baixa intensidade de uma reflexão do que a alta intensidade da exposição direta (pelo menos esse seria o meu “chute”!). No caso de CYMK, nossa sensibilidade chega a ser 4 vezes maior (cerca de 50 milhões de cores perceptíveis).
Mas, para não ficar trabalhando com valores arbitrários, já que podemos criar um mapa de bits diferente para cada um dos componentes (um outro esquema válido, mas menos “preciso”, como exemplo, é usar RGB codificado com 5, 6 e 5 bits, respectivamente), é conveniente que trabalhemos com eles na faixa do intervalo fechado [0,1]. Onde 0 seria “sem cor” e 1 a intensidade máxima do componente.
Este é o padrão normalizado usado pelo OpenGL. Ele é também útil em relação ao componente A (Alpha)… Se A for 0, significa total transparência, se A for 1, significa total opacidade.
Você está vendo a cor correta?!
Como curiosidade, apresendo a você o significado de “gamma correction”. Essa “correção” tenta aproximar, ao máximo, as cores reais de uma cena de sua representação em seu monitor de vídeo. Nossa percepção das cores é exponencial. Não é “linear”… A variação de cores deveria seguir uma curva do tipoc=k·xγ(esse ‘γ’ não é um “ípsilon”, é a letra grega “gamma”), mas seu monitor insiste em mostrar as variações de cores de forma linear e, por isso, é conveniente corrigir essa deficiência.
O “gamma”, no expoente, é um valor, diferente de zero, que pode ser menor que 1 a imagem ficará mais clara, se for maior que 1 ficará mais escura, como mostrado abaixo:
Variando o “gamma” podemos calibrar o espectro de cores do monitor de vídeo ou podemos simular, cuidadosamente, uma iluminação ambiental diferente da original.
Um exemplo do segundo caso é o efeito obtido em certos filmes e sérires, onde os atores parecem estar atuando à noite, mas estão à luz do dia. A “noite” é acrescentada por manipulação, em pós-produção, alterando o gamma e/ou durante a produção, aplicando filtros com lentes polarizadas. O efeito pode ser percebido nas fotos acima…
Se você puder, ajuste o profile de seu monitor, corrigindo o “gamma”, para obter uma imagem mais próxima possível das cores reais. O padrão internacional do valor de “gamma” ideal para monitores de vídeo fica entre 1.8 e 2.2 (onde 2.2 é o preferido). Se você tem um monitor LCD, as chances são de que ele já esteja calibrado (ou bem perto da calibração correta), mas se você tem um CRT, a calibração é obrigatória, caso queira trabalhar com fotografia, por exemplo.
O que vem pela frente…
A noção de que cores são uma propriedade da luz (de fótons) e que o efeito geral depende se ela é refletida ou direta, é importante para um conjunto de conceitos que veremos mais tarde sobre reflexão. Mais especificamente, um modelo matemático mais realista, chamado BRDF (Bidiretional Reflectance Distribution Function). Essa função é um tanto complicada de entender e exige muita preparação, mas essencialmente ela é uma extrapolação do teorema de reflexão Lambertiana (do meu quase “xará”, Johann Heinrich Lambert) e de Fresnel… Você sabe: Aquele que diz que o ângulo de incidência é o mesmo que o ângulo de reflexão!
Bem… não é bem assim! Basta que você já tenha matado aulas para participar de um joguinho de sinuca na cantina pra perceber isso! Quando um conjunto de fótons colidem contra uma superfície eles se espalham. Do mesmo jeito que, quando a bola branca atinge as outras, no topo da mesa, elas se espalham…
A luz refletida é, de fato, espalhada!
Levando isso em consideração, as figuras abaixo mostram a diferença entre uma função de reflexão simples, lambertiana, e o uso da BRDF para a mesma superfície texturizada:
BRDF dá uma idéia mais “realista”, não? Para os mais atentos: Em ambos os casos existe o efeito de “bump mapping”, que fica imperceptível no caso à esquerda…
Não subestime a iluminação e as cores:
Esse pequeno texto introdutório é apenas um aperitivo sobre o vastíssimo campo da iluminação… E olha eu citei apenas duas técnicas de reflexão, e mesmo assim en passant! Além da manipulação vetorial da matéria que compóem um objeto (via seus vértices), muito tem que ser feito para aproximar deformações microscópicas e efeitos de iluminação realistas…
Alguns desses efeitos são muito difíceis de obter por causa da enorme quantidade de cálculo necessário… O efeito de um arco-iris, causado pela refração da luz, é um deles… Claro que existem meios de simulá-lo de forma mais rápida!
Ainda, existem alguns efeitos “artísticos” que são esperados numa animação… “Lens flare”, por exemplo, não é um efeito que consigamos perceber com nossos próprios olhos…
Efeito “lens flare” artificial.
Este é um efeito causado pelas deformações microscópicas de uma lente. E é comum ser artisticamente representado da forma acima, como diversas figuras geometricamente perfeitas semi-transparentes com cores diferentes… Isso ai não acontece desse jeito “no mundo real”.
Deixe-me ressaltar de novo: Computação gráfica é a arte de enganar seus olhos e seu cérebro, fazendo você pensar que está vendo uma imagem tridimensional estampada num plano, no retângulo da tela do seu monitor de vídeo. Com isso, toda a cena é construida a partir de pontos localizados num espaço matemático imaginário de três dimensões (ou quatro) e projetados neste retângulo.
Existem algumas maneiras de fazermos essa projeção. Podemos encarar esse espaço tridimensionais como uma esfera e, neste caso, projetaríamos o interior da esfera no plano que a recortasse em algum lugar… Mas, isso dá muito trabalho, exige muito cálculo complicado, envolvendo funções não lineares como seno e cosseno… Podemos imaginar esse espaço tridimensional como uma caixa de lados paralelos:
Como você pode ver, no caso da caixa, a figura projetada pode parecer “menos” 3D do que deveria, em certos ângulos… Isso acontece porque nossa visão não recebe raios de luz de forma paralela, mas de todos os lados. O que vemos é projetado em nossas retinas, mais ou menos como no retângulo acima, só que usando perspectiva. Se olharmos diretamente para a figura, a veríamos assim:
Para evitar as complexidades de projeções esféricas ou cônicas, adota-se um meio termo entre a projeção cônica (que é a que usamos, fisiologicamente) e a projeção paralela, mostrada acima… Usamos um troço com nome esquisito chamado frustum.
Nosso observador é a câmera. O que está entre os retângulos é o frustum.
O frustum é essa pirâmide sem o topo. Além de ser útil para a projeção perspectiva no plano mais próximo dos nossos olhos (o plano da tela), ele apenas nos permite ver tudo o que está do lado de dentro, e tudo o que está fora dele não pode ser visto.
Note que o frustum é composto de 6 planos. O retângulo que está mais perto da câmera (o pequeno) está num plano chamado “próximo” (near) e o retângulo grandão está num plano chamado “distante” (far). Os outros quatro planos são formados pelos trapézios laterais e planos acima e abaixo. Faz sentido, não?
Se você considerar que a câmera aponta exatamente para o centro do frustum e seu sistema de coordenadas é o mesmo do “mundo” (e, ainda, que a câmera é fixa nesse mundo, ou seja, ela não se mexe — daqui a pouco falo como isso funciona!), então o plano near é definido apenas pela sua coordenada zn e o plano far é definido apenas pela sua coordenada zf. Os cantos do retângulo near são definidos pelas coordenadas xl, xr, yb, yt (onde l vem de left, r vem de right; b, de bottom e t de top):
Na figura, os cantos no plano far são definidos por semelhança de triângulos, exceto pelo componente z.
Usando os planos para selecionar vertices:
Vimos, em outra ocasião, que uma maneira de escrevermos a equação de um plano é usando o vetor normal, unitário, a esse plano e um deslocamento. O vetor normal nos darará a orientação do plano e o deslocamento nos dará…. hummm…. o deslocamento dele em relação a origem.
Vimos também que tudo o que precisamos para calcular um vetor perpendicular a um plano são 3 pontos (ou seja, dois vetores).
Com a equação de um plano podemos calcular a distância de um ponto qualquer em relação a ele… Assim, temos que fazer todos os planos do frustum serem orientados “para dentro”. Qualquer ponto que esteja dentro do frustum apresentará distância “positiva” em relação a todos os 6 planos, caso contrário, se apenas uma distância for negativa, o ponto está fora do frustum.
Obtendo a equação de um plano
Usando o plano near como exemplo, temos que escolher dois lados do retângulo de forma que a ordem destes nos dê um vetor normal “para dentro” do frustum. Para tanto usa-se a “regra da mão direita” e percebe-se que se escolhermos, por exemplo, os vetores v1 e v2, como abaixo, teremos o vetor normal desejado:
Escolha dos vértices…
Onde . No caso do plano near, o vetor normal é, claramente, , e o deslocamento em relação a origem é zn. Isso nos dará a equação para o plano near: . onde z é a icógnita e zn é a distância do plano à origem.
Não precisamos “calcular” zn aqui porque ele é um dado. Ele é a distância dos seus olhos ao seu monitor, mas quando você têm pontos arbitrários no espaço, a maneira de calcular esse deslocamento é através da projeção de qualquer ponto contido no plano sobre o vetor normal que acabamos de calcular. Para isso podemos usar o produto escalar.
Existe uma coisa estranha aqui, não? Anteriormente definimos a equação de um plano como:
Então, porque d agora entra subtraindo? Acontece que precisamos saber o se um ponto qualquer está “na frente”, “sobre” ou “atrás” do plano. Quando fazemos o produto escalar de um ponto qualquer com o vetor normal (e é isso que estamos fazendo ao multiplicar a,b e c por x,y e z, na equação acima), obtemos a distancia desse ponto em relação a origem do sistema de coordenadas. Essa distância, subtraída de d nos dirá se estamos antes, em cima ou depois de um ponto qualquer do plano.
Eis um exemplo: Por agora, vamos definir o plano near como distanciado de 1 metro de nossos olhos . Se quisermos determinar se o ponto está dentro ou fora do frustum, só precisamos colocar essas coordenadas na equação do plano near. Repare que a equação desse plano em particular só leva z em consideração, portanto, o resultado de substituir z por nos dará . Com esse valor negativo, sabemos que o ponto encontra-se a uma distância negativa do plano, ou seja, está do “lado de trás” dele.
O mesmo exemplo com um ponto “na frente” do plano: Se tivermos um ponto em , então Pnear=3. A distância é positiva. Repare que qualquer ponto com coordenada z=1 estará sempre “em cima” do plano, já que .
Projetando os pontos dentro do frustum no plano near:
Usar o frustum para decidir se um ou mais vértices devem ser considerados na hora de desenharmos um objeto não é a única utilidade dele… Ele serve para projetarmos todos os objetos que se encontram “do lado de dentro” sobre o plano near. Trata-se de uma transformação geométrica… Não seria ótimo se pudéssemos ter uma matriz de transformação que fizesse essas projeções por nós? Essa matriz, é claro, existe e é bem complicada:
A matriz acima é chamada de matriz de projeção perspectiva. Existe outra, incorporada no OpenGL, chamada matriz de projeção ortogonal, que faz a mesma coisa, só que lembra a caixa de lados paralelos que falei antes. Ela não nos é muito útil, do ponto de vista do realismo, já que não nos oferece um efeito conhecido na fotografia e no desenho como “pontos de fuga”:
Desenho com um ponto de fuga.
Sem o ponto de fuga, a figura acima ficaria “quadrada” e, como consequência, menos “real”. O que a matriz anterior faz é colocar o ponto de fuga refletido em relação ao olho do observador (hã? como assim? calma, explico!) e, como todas as outras matrizes, transformar um sistema de coordenadas em outro. No caso, o sistema da câmera (eye space) num outro sistema chamado de clipping space, que também é tridimensional, mas tem características especiais que facilitam o “recorte” de polígonos que se encontram dentro ou fora do frustum. O espaço de recorte (clipping space) é definido como um cubo onde suas coordenadas mais extremas estão definidas na faixa .
O lance do ponto de fuga refletido é porque a matriz acima transforma o frustum em uma caixa com lados paralelos. Assim, a parte de trás do frustum é “comprimida” em relação a parte da frente. O efeito é que o ponto de fuga não estará no olho do observador (como pode parecer no desenho conceitual do frustum, lá em cima), mas à sua frente, com a taxa de compressão dos pixels, no plano near, de :
O cubo tem lados iguais, mas parece menor “atrás”.
Essa compressão na frente do plano near gera um problema de precisão nos cálculos com valores em ponto flutuante: Quanto mais afastado estiver um ponto do plano near, menos precisa será a sua posição… Isso não importa muito, já que tendemos a perder os detalhes de objetos que estejam longe, de qualquer forma.
Não vou debulhar a matriz de projeção para você… Se quiser ler um artigo onde alguém explica como chegar nela, recomendo ler este aqui. Para os fins deste artigo é suficiente saber que a matriz é obtida por semelhança de triângulos, levando em conta os limites da “caixa” do clipping space e há uma inversão do sentido no eixo z. Esse sistema de coordenadas também é chamado de sistema de coordenadas normalizado do dispositivo (NDC, Normalize Device Coordinates).
Minha intenção em te mostrar essa matriz de transformação é para deixá-lo ciente que este é apenas um modelo de projeção. Sua aplicação pode exigir um modelo diferente. Entender que estamos fazendo uma projeção no plano da tela e que estamos usando uma matriz única para isso é essencial para que você crie seus próprios modelos de projeção, se precisar… Não que vá precisar de um tão cedo: A maioria das aplicações em computação gráfica usam esse modelo ai em cima… Mas, pode ser que você queira acrescentar outro ponto de fuga ou criar uma projeção que dê um efeito “olho de peixe”, por exemplo. Já sabe onde deve fazer isso, mesmo que não saiba como!
Com relação à definição da matriz, algumas funções, como a antiga (e fora de uso) gluPerspective(), usam o valor zn, zf, uma “taxa de aspecto” e um ângulo de abertura, para calcular o campo de visão e achar, tanto o retângulo near quanto o far… Bibliotecas como a glm ainda possuem funções assim, que calcularão a matriz de projeção para você.
Como orientar a câmera?
Se o frustum é definido de acordo com uma câmera estática, localizada na origem do sistema de coordenadas e apontando sempre para z=-1, então como é que posso movê-la? A resposta simples é: Não pode!
A resposta complicada, que talvez “exploda a sua cabeça” é a mesma que o pequeno aspirante a Buda falou para Neo, em Matrix: “Não tente entortar a colher, entorte o mundo!” (bem… não foi bem isso o que ele falou no filme, mas você pegou a ideia, né?).
Isso ai… ao aplicar as matrizes de transformação de translação, rotação e escalonamento, lá no espaço do mundo, você estará movendo o mundo, não a câmera! Em essência, a câmera fica parada, o mundo é que se move!
No modo “compatível” do OpenGL (compatível com o OpenGL 2.1) fazíamos isso usando uma matriz de transformação do mundo diferente para cada conjunto de vértices de objetos e uma matriz de transformação “global” para posicionar o mundo do jeito que queríamos (via função gluLookAt). Ainda precisaremos fazer isso no OpenGL 3.1 ou superior, mas a maneira de fazê-lo é via shaders. Especificamente, via vertex shaders, que veremos numa outra ocasião…
Assim, as coordenadas que definem o frustum o fazem nas coordenadas do mundo. Quando você move o mundo, move o frustum junto com ele.
O quê? Você não se lembra da propaganda da bala de leite Kids? Assista essa velharia aqui. Tô ficando velho, huh?
Como prometi, eis a explicação sobre as matrizes de transformação de rotação. Para falar delas em 3D tenho que mostrar como elas foram obtidas em 2D, no plano cartesiano. Nesse caso, a matriz é assim:
Essa matriz rotaciona o vetor num ângulo θ (theta), no sentido anti-horário. E eis como ela foi obtida: Considere um vetor de tamanho R arranjado numa inclinação qualquer que chamarei de Φ (phy). Queremos rotacioná-lo de acordo com um ângulo θ (theta), como mostrado abaixo:
Olhando para o gráfico podemos dizer que:
Para obter x’ e y’ precisamos usar a identidade da soma de ângulos das funções trigonométricas de seno e cosseno… Isso nos dá:
Dá pra perceber que, se e se , podemos substituir isso na equação acima e obtermos exatamente a matriz de rotação…
Por que precisamos de 3 matrizes de rotação em 3D?
Existe um meio de calcularmos uma rotação em 3D usando um modelo vetorial chamado quartenion. Quartenions são números complexos de 4 dimensões (diferente dos números complexos tradicionais, que tem um componente “real” um “imaginário”, quartenions tem 3 componentes “imaginários”).
Acontece que isso é um tópico um pouco mais avançadado que deixarei para outra oportunidade. Assim, o método mais simples, por enquanto, é realizar rotações em torno dos eixos individualmente:
Os termos pitch, yaw e roll foram tomados emprestados da aviação. Repare que os eixos são rotacionados no sentido de uma outra “regra da mão direita”, onde abraçamos o eixo com os dedos, deixando o polegar levantado (no sinal de “positivo”) e seguindo o sentido do eixo:
Os dedos indicador, médio anular e mínimo dão o sentido positivo de rotação…
As rotações individuais podem ser entendidas como se estivéssemos realizando rotações em planos cartesianos individuais. Ao rotacionar em torno de z rotacionamos o plano xy, ao rotarcionarmos em torno de x, rotacionamos o plano yz e, por último, em torno de y, o plano zx. No caso da rotação em torno de z, alteraremos os valores de x e y, deixando o componente z inalterado. Algo similar acontece com as outras rotações.
As matrizes:
As matrizes de rotação ficam assim:
O motivo pela inversão dos sinais dos senos, na matriz Ry é que, para adotar o padrão da regra da mão direita, temos que inverter o sentido de rotação “em torno” do eixo y.
Abaixo temos os efeitos da aplicação de cada uma das matrizes, individualmente, a partir de um conjunto de vértices não rotacionados e um ângulo θ de 30° (ou π/6 radianos):
O primeiro cubo não está rotacionado…
Para fazer rotações mais complexas você pode multiplicar matrizes de rotação e, como expliquei num artigo anterior, as matrizes de rotação são inversíveis e ortogonais, portanto, para obter suas inversas basta transpô-las… Assim, você pode querer fazer uma rotação, seguida de alguma outra transformação e, depois, a rotação no sentido inverso. Bastando fazer: .
Essa é mais ou menos a técnica que o OpenGL usa para realizar rotações em torno de vetores arbitrários (ao invés de apenas em torno de vetores diretores!). Ele toma todos os vértices do objeto e os rotaciona de forma que o vetor sobre o qual queremos rotacionar fique alinhado com um vetor diretor… Depois realiza a rotação desejada e dezfaz a rotação de alinhamento. No exemplo acima, R seria a rotação de alinhamento e T a rotação desejada para o objeto em torno do vetor arbitrario…
Já escrevi, aqui, brevemente, sobre áudio em 3D. Quero só reforçar o conceito e mostrar que quase tudo o que você viu até agora não se aplica somente a gráficos.
A idéia de “computação gráfica” tridimensional é enganar seus olhos e seu cérebro, fazendo você pensar que está vendo um troço 3D quando, na verdade, está vendo uma imagem estampada num retângulo plano, na tela de seu computador. Com áudio a coisa é um pouco diferente. Os transdutores (alto-falantes) podem estar posicionados bem próximo às suas orelhas quando você usa um headphone ou em torno de você quando usa um equipamento capaz de reproduzir som Dolby. De qualquer maneira, som 3D é algo que você realmente obtém, não há muito como enganar o usuário.
Felizmente, já que o teor de enganação é menor, toda a matemática fica um pouco mais simples: Não temos diversos sistemas de coordenadas, temos só um, onde sua cabeça é o centro do mundo… Ok, podemos ter dois sistemas: Um onde os objetos são posicionados de forma absoluta e outro que é uma transformação deste último, para efeitos de posicionamento da origem. Mas é isso! Nada de projeções perspectivas, nada de recortes, nada de “cores” e “texturas”…
O espaço do áudio
O sistema de coordenadas de áudio tridimensional é, basicamente, o mesmo que o usado no “espaço do mundo”. Só que temos objetos bem definidos que simbolizam as fontes de áudio (os “emissores de som”) e o ouvinte (listener, ou seja, você!). Nesse sistema de coordenadas temos um centro e os vetores diretores que compõem os eixos do sistema crescem para direita (x), para cima (y) e em sua direção (z — ou seja, z > 0 na parte de trás de sua cabeça!).
Os dois objetos que ocupam esse espaço
Primeiro, existe o listener. Ele é definido por sua posição no espaço e por dois vetores diretores. O vetor frontal (que diz para onde você está olhando) e o vetor “para cima”. Afinal, você pode estar olhando “para frente”, mas pode estar com a cabeça virada ou de cabeça-para-baixo, não pode?
Esses dois vetores devem ser unitários e perpendiculares. Bem…. Na verdade, o vetor “para cima” não precisa ser perpendicular. Os algorítmos que usam esse vetor tomarão conta disso (veremos isso em um outro texto). O fato é que, com base nesses 3 vetores (posição, para-frente e para-cima), podemos saber onde está o seu ouvido direito e onde está o seu ouvido esquerdo…
É possível definir vários listeners numa cena, mas só um estará ativo de cada vez. Só existe um cérebro na sua cabeça e um conjunto de dois ouvidos… A não ser que você seja um alienígena lendo esse texto (neste caso: bem vindo!).
Os outros objetos que podem ser colocados nesse esapço são as “fontes de áudio” (sources). O modelo usado por essas fontes não é tão bom quanto poderia ser: Só é necessário um conjunto de coordenadas para definir sua posição e é só! Outros atributos são relacionados ao áudio em si, mas não existe nenhum cálculo relativo à reverberação (a refração sonora) ou atenuações quando a onda passa por matéria de densidade diferente… Se você quiser fazer isso, terá que mexer na forma de onda da fonte sonora por si mesmo… E isso dá um trabalho dos diabos.
O áudio de uma fonte
Cada fonte de áudio trabalha com um buffer contendo áudio monofônico, ou seja, com apenas um canal. Isso faz sentido, na medida que toda fonte de áudio emite apenas um som que pode ser combinado com outras fontes para montar um áudio mais complexo e localizado em diversos lugares.
Isso ainda facilita um bocado o tratamento da forma de onda da fonte. Embora não haja como realizar alguns efeitos 3D através das propriedades do objeto source, existem sim alguns atributos que podem ser úteis: Bibliotecas como OpenAL suportam efeito Doppler associando um vetor de velocidade, tanto às fontes, quanto ao listener. As fontes de áudio podem também ser direcionadas através de um cone de áudio… Podemos alterar o ganho na amplificação do áudio, independente da distância em que esse se encontra do listener (também podemos dizer se o listener é mais surdo ou se ouve muito bem alterando o seu ganho)… Para os sources também há como especificar um delay que, combinando com o áudio de outro source pode-se emular eco…
Como bibliotecas como OpenAL funcionam?
Quando ao posicionamento espacial, lateral, a coisa é bem óbia… se uma fonte áudio está à sua direita, a intensidade do som, no canal direito, será mais intensa que no canal esquedo. Isso é determinado pela distância entre a fonte e o ouvinte. O efeito final: Parece mesmo que a fonte, que está a direita no espaço de áudio, estará mesmo à direita, de acordo com sua percepção,
Mas, e quanto os eixos y e z?
No áudio estereofônico (stereo), o efeito do posicionamento do ponto focal é obtido mudando a “diferença de fase” dos áudios que são colocados nos seus ouvidos. Se houver uma pequena diferença de tempo entre a percepção de um ouvido em relação a outro, você interpreta como se esse áudio estivesse na sua frente ou atrás. Isso resolve a sensação de distância frontal…
Infelizmente nossa percepção sonora do que será acima ou abaixo não é tão boa. Ela pode ser acentuada com um efeito de eco, combinada com os outros dois efeitos de distância e fase e, ainda, a adição de uma onda de alta-frequência (7 kHz ou superior). É uma coisa complicada de fazer e está relacionada com algumas características fisiológicas.
Outra maneira de determinar a altura de uma fonte de áudio é movendo a sua cabeça. Como o posicionamento frontal da fonte muda, nossos cérebros adaptam o modelo para localizá-lo…. Não precisa nem dizer que, no mundo virtual, isso não é lá muito fácil de fazer, né?
Para não ficar muito complicado, as distorções no eixo y não são lá muito levadas em conta… Procure um desses vídeos de teste de percepção auditiva que você verá que, ao fechar os olhos, você percebe muito bem as fontes laterais e, com um mínimo de esforço, as fontes “atrás” e “na frente”… Mas, terá problemas em perceber “acima” ou “abaixo”. Por isso, eles nem tentam!
Dando uma ajudinha, via hardware
É possível acentuar a percepção do eixo y se você tiver um home theater com som Dolby com 6 canais (Dolby 5.1) ou mais…. basta posicionar as caixas de som de forma que elas não fiquem no mesmo plano… Mas, para isso, seu programa deverá saber o posicionamento espacial no mundo real, para poder calcular melhor a distribuição do áudio.
Isso raramente é feito porque dá um trabalho dos diabos!


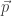


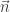







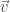


 ) e calcular a distância do observador ao plano… Na equação, o vetor
) e calcular a distância do observador ao plano… Na equação, o vetor  . Onde n é a quantidade de vértices… No nosso caso, 4 (uma vez que teremos 4 planos, um para cada triângulo). Neste ponto não precisamos calcular a centroide de cada um dos triângulos nos planos, já que a centroide do tetraedro ainda é a média aritmética simples de cada um dos vértices!
. Onde n é a quantidade de vértices… No nosso caso, 4 (uma vez que teremos 4 planos, um para cada triângulo). Neste ponto não precisamos calcular a centroide de cada um dos triângulos nos planos, já que a centroide do tetraedro ainda é a média aritmética simples de cada um dos vértices!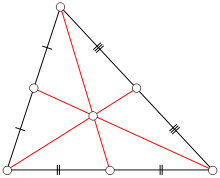
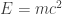 usa o sinal de igualdade para expressar que duas ou mais grandezas, geralmente diferentes, são equivalentes. Existe uma grandeza do lado esquerdo (energia, neste exemplo) e outras do lado direito (massa e velocidade). É assumido, mas não necessariamente obrigatório, que a expressão do lado esquerdo seja uma consequência da expressão do lado direito…
usa o sinal de igualdade para expressar que duas ou mais grandezas, geralmente diferentes, são equivalentes. Existe uma grandeza do lado esquerdo (energia, neste exemplo) e outras do lado direito (massa e velocidade). É assumido, mas não necessariamente obrigatório, que a expressão do lado esquerdo seja uma consequência da expressão do lado direito… … Acontece que isso é, do ponto de vista Físico, inválido… O sinal de igualdade não é uma simples atribuição e as grandezas geralmente não são “intercambiáveis”.
… Acontece que isso é, do ponto de vista Físico, inválido… O sinal de igualdade não é uma simples atribuição e as grandezas geralmente não são “intercambiáveis”. , embora o resultado, no lado esquerdo, seja um vetor e a variável independente, do lado direito, seja também um vetor (
, embora o resultado, no lado esquerdo, seja um vetor e a variável independente, do lado direito, seja também um vetor ( , onde I e M são matrizes de transformação geométricas. Ao multiplicar um vetor por uma matriz estamos “transformando” o vetor, usando vetores diretores de outro espaço, diferentes do “espaço canônico”.
, onde I e M são matrizes de transformação geométricas. Ao multiplicar um vetor por uma matriz estamos “transformando” o vetor, usando vetores diretores de outro espaço, diferentes do “espaço canônico”. ,
,  e
e  .
. , que está no espaço canônico, é equivalente ao vetor
, que está no espaço canônico, é equivalente ao vetor 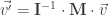 . E, já que a matriz de identidade é ortogonal, então
. E, já que a matriz de identidade é ortogonal, então 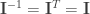 , podemos, seguramente ignorar
, podemos, seguramente ignorar 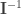 , neste caso.
, neste caso. na base canônica e tenhamos uma base arbitrária A contendo 3 vetores diretores ortogonais como abaixo:
na base canônica e tenhamos uma base arbitrária A contendo 3 vetores diretores ortogonais como abaixo:
 e
e  rotacionados em 45° no sentido anti-horário (
rotacionados em 45° no sentido anti-horário ( ), mas o vetor diretor
), mas o vetor diretor  manteve-se. Ou seja, nesse exemplo, nosso novo sistema de coordenadas será rotacionado em 45° para a esquerda em torno do eixo z (veja a próxima figura!).
manteve-se. Ou seja, nesse exemplo, nosso novo sistema de coordenadas será rotacionado em 45° para a esquerda em torno do eixo z (veja a próxima figura!). . Assim, transpondo a matriz e multiplicando-a pelo vetor
. Assim, transpondo a matriz e multiplicando-a pelo vetor 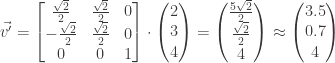
 está exatamente no mesmo lugar do ponto
está exatamente no mesmo lugar do ponto  , mas num sistema de coordenadas diferente!
, mas num sistema de coordenadas diferente!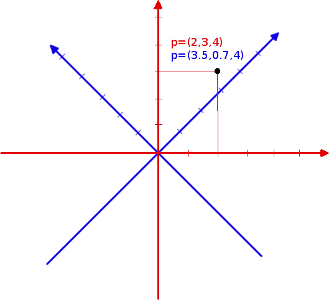
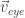 ), um vetor “para frente” (
), um vetor “para frente” ( ) e um vetor “para cima” (
) e um vetor “para cima” ( ). O vetor
). O vetor  e possui os vetores
e possui os vetores 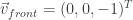 e
e  .
. (indica uma posição no espaço do mundo para onde a câmera aponta) e
(indica uma posição no espaço do mundo para onde a câmera aponta) e  . Assim, temos dois vetores diretores (
. Assim, temos dois vetores diretores ( (repare na ordem!).
(repare na ordem!).
 ,
, 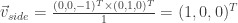 e
e 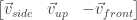 . O motivo de invertermos o sentido do vetor diretor
. O motivo de invertermos o sentido do vetor diretor 
 , onde a primeira a matriz do “modelo” transforma os vértices dos objetos no espaço do modelo para o “mundo” e a matriz da câmera (ou “visão”) transforma os vértices que estão no “mundo” para o espaço da câmera, alterando a base do sistema de coordenadas, como mostrado acima.
, onde a primeira a matriz do “modelo” transforma os vértices dos objetos no espaço do modelo para o “mundo” e a matriz da câmera (ou “visão”) transforma os vértices que estão no “mundo” para o espaço da câmera, alterando a base do sistema de coordenadas, como mostrado acima. e
e  , mas com a matriz do modelo ajustada para a matriz identidade.
, mas com a matriz do modelo ajustada para a matriz identidade. , lembra?) e desenhá-los antes de todos os outros. O processo tem que ser repetido para os objetos que sobram até que não reste objetos a serem desenhados…
, lembra?) e desenhá-los antes de todos os outros. O processo tem que ser repetido para os objetos que sobram até que não reste objetos a serem desenhados…
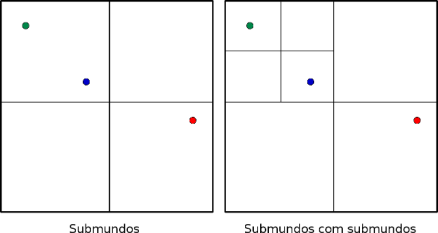
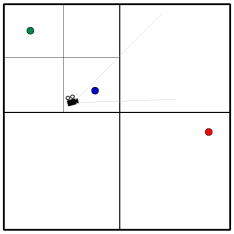
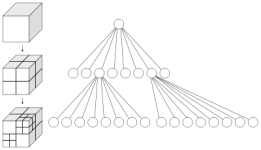
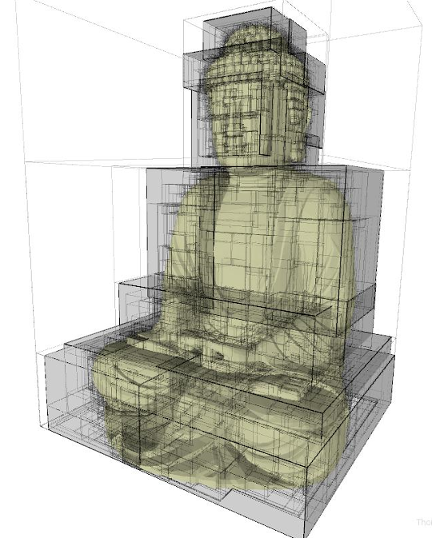

 Eis um exemplo, ao lado, de uma árvore BSP montada à partir da figura acima. Os nós do lado esquerdo estão “na frente” dos planos (os vetores normais dos planos divisores nos dão a orientação). Os do lado direito, “atrás”. Este exemplo simples não parece lá muito convincente, mas, uma vez que determinarmos que o que está “na frente” do plano B não está dentro do frustum, não precisamos nos preocupar com a sub-árvore à esquerda do nó deste plano.
Eis um exemplo, ao lado, de uma árvore BSP montada à partir da figura acima. Os nós do lado esquerdo estão “na frente” dos planos (os vetores normais dos planos divisores nos dão a orientação). Os do lado direito, “atrás”. Este exemplo simples não parece lá muito convincente, mas, uma vez que determinarmos que o que está “na frente” do plano B não está dentro do frustum, não precisamos nos preocupar com a sub-árvore à esquerda do nó deste plano.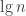 (logaritmo, na base 2, de n).
(logaritmo, na base 2, de n). ou
ou  , onde as constantes a é chaamada a parte “real” e b, a parte “imaginária”. Óbviamente não se trata de imaginação, no sentido de que tudo é possível, mas somente a nomenclatura oposta de “real” (o que não é real é “imaginado”, não é?). A parte “real” também é óbvia. Refere-se ao domínio ℝ. Uma maneira de pensar em números complexos é encará-los como uma forma algébrica de especificar um vetor
, onde as constantes a é chaamada a parte “real” e b, a parte “imaginária”. Óbviamente não se trata de imaginação, no sentido de que tudo é possível, mas somente a nomenclatura oposta de “real” (o que não é real é “imaginado”, não é?). A parte “real” também é óbvia. Refere-se ao domínio ℝ. Uma maneira de pensar em números complexos é encará-los como uma forma algébrica de especificar um vetor 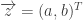 :
: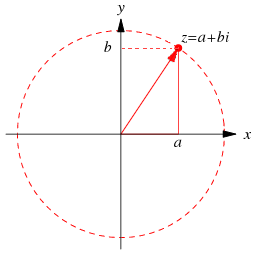
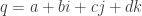 , onde i, j e k são os componentes imaginários. Para facilitar a associação de um quaternion com vetores no espaço tridimensional vou inverter a notação para
, onde i, j e k são os componentes imaginários. Para facilitar a associação de um quaternion com vetores no espaço tridimensional vou inverter a notação para  , onde d é o valor real isolado. Essa notação pode ser escrita, também como
, onde d é o valor real isolado. Essa notação pode ser escrita, também como  , onde
, onde  . O motivo de usarmos delimitadores < e > nessa notação é que podemos querer escrever algo assim:
. O motivo de usarmos delimitadores < e > nessa notação é que podemos querer escrever algo assim:  .
.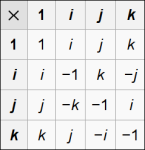
 . Mas também podemos escrever a mesma coisa usando a notação complexa, usando os valores i, j e k, complexos, que seguem características mostradas na tabela ao lado.
. Mas também podemos escrever a mesma coisa usando a notação complexa, usando os valores i, j e k, complexos, que seguem características mostradas na tabela ao lado. . Repare, também, que o produto entre esses valores não é comutativo, ou seja,
. Repare, também, que o produto entre esses valores não é comutativo, ou seja, 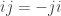 , por exemplo. Esse último fato te lembra de alguma coisa? Essas multiplicações (entre i, j e k) lembram o produto vetorial entre os vetores diretores de um sistema de coordenadas ortogonal (por exemplo,
, por exemplo. Esse último fato te lembra de alguma coisa? Essas multiplicações (entre i, j e k) lembram o produto vetorial entre os vetores diretores de um sistema de coordenadas ortogonal (por exemplo, 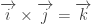 ), não lembram?
), não lembram? é “puro”.
é “puro”. , para
, para  e
e  , definido de maneira similar, então
, definido de maneira similar, então  . No escalonamento:
. No escalonamento:  . Mas a coisa começa a ficar interessante com a multiplicação…
. Mas a coisa começa a ficar interessante com a multiplicação…
 .
. ) temos que usar o “macete”:
) temos que usar o “macete”:
 é o conjugado do quaternion q, onde invertemos apenas o sinal do vetor
é o conjugado do quaternion q, onde invertemos apenas o sinal do vetor 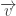 , refletindo-o (se
, refletindo-o (se  então
então 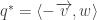 ). O tamanho de um quaternion é obtido da maneira tradicional:
). O tamanho de um quaternion é obtido da maneira tradicional: 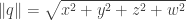 .
. ), então
), então  .
. ), facilmente:
), facilmente:
 , deste jeito:
, deste jeito:  , onde o quaternion p é dado por
, onde o quaternion p é dado por  e o quaternion q contém o vetor unitário
e o quaternion q contém o vetor unitário  ). A interpretação geométrica dessa multiplicação de quaternions pode ser entendida como se o primeiro rotacionasse o vetor
). A interpretação geométrica dessa multiplicação de quaternions pode ser entendida como se o primeiro rotacionasse o vetor 
 O artista que pinta os modelos o faz através de decalques. Ai do lado tem um exemplo simples do que é um decalque, mas estou certo de que você já tinha mexido com isso antes. Isso é bem semelhante ao que acontece dentro da aplicação: Uma imagem é estampada, pixel por pixel, sobre alguma superfície tridimensional. Ela sofre alguma deformação por causa da interpolação necessária para fazê-la caber na superfície e este é o aspecto matemático da coisa..
O artista que pinta os modelos o faz através de decalques. Ai do lado tem um exemplo simples do que é um decalque, mas estou certo de que você já tinha mexido com isso antes. Isso é bem semelhante ao que acontece dentro da aplicação: Uma imagem é estampada, pixel por pixel, sobre alguma superfície tridimensional. Ela sofre alguma deformação por causa da interpolação necessária para fazê-la caber na superfície e este é o aspecto matemático da coisa..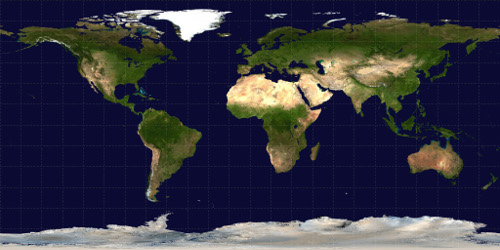


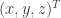 . Agora, além desses três valores, temos mais dois:
. Agora, além desses três valores, temos mais dois:  , onde s corresponde à componente horizontal e q, à vertical (veja a minha cara de malandro ai em cima!). Assim, além da posição do vértice no espaço do modelo, temos que especificar a coordenada deste vértice no espaço das texturas para que o OpenGL saiba quais pixels deve copiar da textura para a superfície e, ainda mais, como ele vai interpolar os pixels contidos na textura para caber na superfície, depois de transformada no espaço do mundo.
, onde s corresponde à componente horizontal e q, à vertical (veja a minha cara de malandro ai em cima!). Assim, além da posição do vértice no espaço do modelo, temos que especificar a coordenada deste vértice no espaço das texturas para que o OpenGL saiba quais pixels deve copiar da textura para a superfície e, ainda mais, como ele vai interpolar os pixels contidos na textura para caber na superfície, depois de transformada no espaço do mundo.

 . A face frontal encontra-se em
. A face frontal encontra-se em  :
: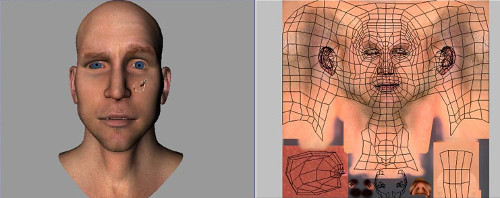



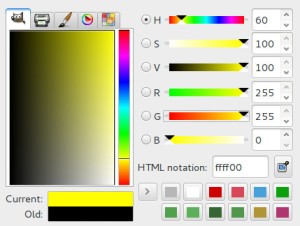



 Variando o “gamma” podemos calibrar o espectro de cores do monitor de vídeo ou podemos simular, cuidadosamente, uma iluminação ambiental diferente da original.
Variando o “gamma” podemos calibrar o espectro de cores do monitor de vídeo ou podemos simular, cuidadosamente, uma iluminação ambiental diferente da original.


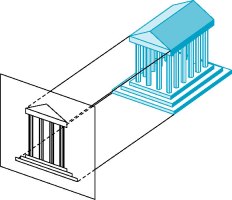
 Para evitar as complexidades de projeções esféricas ou cônicas, adota-se um meio termo entre a projeção cônica (que é a que usamos, fisiologicamente) e a projeção paralela, mostrada acima… Usamos um troço com nome esquisito chamado frustum.
Para evitar as complexidades de projeções esféricas ou cônicas, adota-se um meio termo entre a projeção cônica (que é a que usamos, fisiologicamente) e a projeção paralela, mostrada acima… Usamos um troço com nome esquisito chamado frustum.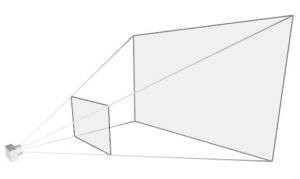
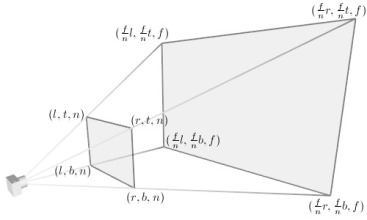

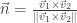 . No caso do plano near, o vetor normal é, claramente,
. No caso do plano near, o vetor normal é, claramente,  , e o deslocamento em relação a origem é zn. Isso nos dará a equação para o plano near:
, e o deslocamento em relação a origem é zn. Isso nos dará a equação para o plano near:  . onde z é a icógnita e zn é a distância do plano à origem.
. onde z é a icógnita e zn é a distância do plano à origem.
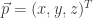 com o vetor normal (e é isso que estamos fazendo ao multiplicar a,b e c por x,y e z, na equação acima), obtemos a distancia desse ponto em relação a origem do sistema de coordenadas. Essa distância, subtraída de d nos dirá se estamos antes, em cima ou depois de um ponto qualquer do plano.
com o vetor normal (e é isso que estamos fazendo ao multiplicar a,b e c por x,y e z, na equação acima), obtemos a distancia desse ponto em relação a origem do sistema de coordenadas. Essa distância, subtraída de d nos dirá se estamos antes, em cima ou depois de um ponto qualquer do plano. . Se quisermos determinar se o ponto
. Se quisermos determinar se o ponto  está dentro ou fora do frustum, só precisamos colocar essas coordenadas na equação do plano near. Repare que a equação desse plano em particular só leva z em consideração, portanto, o resultado de substituir z por
está dentro ou fora do frustum, só precisamos colocar essas coordenadas na equação do plano near. Repare que a equação desse plano em particular só leva z em consideração, portanto, o resultado de substituir z por  nos dará
nos dará  . Com esse valor negativo, sabemos que o ponto
. Com esse valor negativo, sabemos que o ponto  encontra-se a uma distância negativa do plano, ou seja, está do “lado de trás” dele.
encontra-se a uma distância negativa do plano, ou seja, está do “lado de trás” dele. , então Pnear=3. A distância é positiva. Repare que qualquer ponto com coordenada z=1 estará sempre “em cima” do plano, já que
, então Pnear=3. A distância é positiva. Repare que qualquer ponto com coordenada z=1 estará sempre “em cima” do plano, já que  .
.
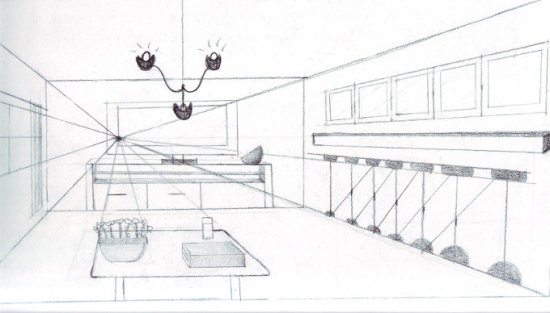
![\left [ -1 \dots +1\right ]](https://s0.wp.com/latex.php?latex=%5Cleft+%5B+-1+%5Cdots+%2B1%5Cright+%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.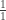 :
: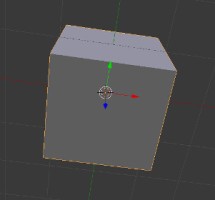

 num ângulo θ (theta), no sentido anti-horário. E eis como ela foi obtida: Considere um vetor de tamanho R arranjado numa inclinação qualquer que chamarei de Φ (phy). Queremos rotacioná-lo de acordo com um ângulo θ (theta), como mostrado abaixo:
num ângulo θ (theta), no sentido anti-horário. E eis como ela foi obtida: Considere um vetor de tamanho R arranjado numa inclinação qualquer que chamarei de Φ (phy). Queremos rotacioná-lo de acordo com um ângulo θ (theta), como mostrado abaixo: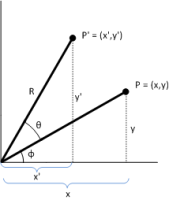


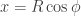 e se
e se 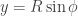 , podemos substituir isso na equação acima e obtermos exatamente a matriz de rotação…
, podemos substituir isso na equação acima e obtermos exatamente a matriz de rotação…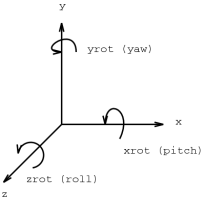
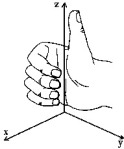

 .
. e os vetores diretores que compõem os eixos do sistema crescem para direita (x), para cima (y) e em sua direção (z — ou seja, z > 0 na parte de trás de sua cabeça!).
e os vetores diretores que compõem os eixos do sistema crescem para direita (x), para cima (y) e em sua direção (z — ou seja, z > 0 na parte de trás de sua cabeça!).
Você precisa fazer login para comentar.